
本系列博文主要根据开源的thorough-pytorch项目编写,感谢datawhalechina团队的dalao们分享学习经验
PyTorch训练模型
一个神经网络的典型训练过程如下:
- 定义包含一些可学习参数(或者叫权重)的神经网络
- 在输入数据集上迭代
- 通过网络处理输入
- 计算损失函数
loss(输出和正确答案的距离) - 将梯度反向传播给网络的参数
- 更新权重(一般使用简单的规则,如
weight = weight - learning_rate * gradient)
下面来分别介绍其中的关键流程在PyTorch上的实现
损失函数
损失函数可以被理解成模型训练结果的负反馈,即数据输入到模型当中产生的结果与真实标签的评价指标,模型可以按照损失函数的目标来做出改进
通过torch.nn可以调用PyTorch中内置的损失函数,也可以自行搭建模型的损失函数
二分类交叉熵损失函数
使用下面的函数计算二分类任务时的交叉熵(Cross Entropy)
在二分类中,label是0或1中的一个,因此对于进入交叉熵函数的输入为概率分布的形式
1 | torch.nn.BCELoss( |
一般来说,input为sigmoid激活层的输出,或者softmax的输出
计算公式如下:
$$
\ell(x, y)=\left{\begin{array}{ll}
\operatorname{mean}(L), & \text { if reduction }=\text { ‘mean’ } \
\newline
\operatorname{sum}(L), & \text { if reduction }=\text { ‘sum’ }
\end{array}\right.
$$
交叉熵损失函数
上面二分类交叉熵损失函数的推广
1 | torch.nn.CrossEntropyLoss( |
计算公式如下:
$$
\operatorname{loss}(x, \text { class })=-\log \left(\frac{\exp (x[\text { class }])}{\sum_{j} \exp (x[j])}\right)=-x[\text { class }]+\log \left(\sum_{j} \exp (x[j])\right)
$$
1 | loss = nn.CrossEntropyLoss() |
L1损失函数
用这个函数计算得到结果与真实标签之间差值的绝对值
1 | torch.nn.L1Loss( |
其中reduction可以选择三种模式:
- none:逐个元素计算
- sum:所有元素求和
- mean:加权平均
计算公式如下:
$$
L_{n} = | x_{n}-y_{n}|g)
$$
MSE损失函数
使用下面的函数计算得到结果与真实标签之间差值的平方
1 | torch.nn.MSELoss( |
计算公式如下:
$$
l_{n}=\left(x_{n}-y_{n}\right)^{2}
$$
平滑L1损失函数
1 | torch.nn.SmoothL1Loss( |
是L1的平滑输出,能够减轻离群点带来的影响
计算公式如下:
$$
\operatorname{loss}(x, y)=\frac{1}{n} \sum_{i=1}^{n} z_{i}
$$
其中,
$$
z_{i}=\left{\begin{array}{ll}
0.5\left(x_{i}-y_{i}\right)^{2}, & \text { if }\left|x_{i}-y_{i}\right|<1 \
\newline
\left|x_{i}-y_{i}\right|-0.5, & \text { otherwise }
\end{array}\right.
$$
1 | loss = nn.SmoothL1Loss() |
通过可视化两种损失函数曲线来对比平滑L1和L1两种损失函数的区别
1 | inputs = torch.linspace(-10, 10, steps=5000) |
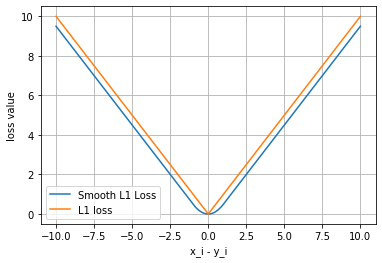
可以看得出来,对于smoothL1来说,在0这个尖端处,过度更为平滑。
余弦相似度
计算公式:
$$
\operatorname{loss}(x, y)=\left{\begin{array}{ll}
1-\cos \left(x_{1}, x_{2}\right), & \text { if } y=1 \
\newline
\max \left{0, \cos \left(x_{1}, x_{2}\right)-\text { margin }\right}, & \text { if } y=-1
\end{array}\right.
$$
其中,
$$
\cos (\theta)=\frac{A \cdot B}{|A||B|}=\frac{\sum_{i=1}^{n} A_{i} \times B_{i}}{\sqrt{\sum_{i=1}^{n}\left(A_{i}\right)^{2}} \times \sqrt{\sum_{i=1}^{n}\left(B_{i}\right)^{2}}}
$$
这个损失函数应该是最广为人知道的,即对于两个向量做余弦相似度,如果两个向量的距离近,则损失函数值小,反之亦然。
这个函数可以有效确定向量之间推广的欧式距离
1 | torch.nn.CosineEmbeddingLoss( |
其他损失函数
PyTorch内部支持了大量损失函数,可以查阅官方文档或本教程的原版repo了解详细内容,这里仅列举如下
目标泊松分布的负对数似然损失
1
2
3
4
5
6
7
8torch.nn.PoissonNLLLoss(
log_input=True,
full=False,
size_average=None,
eps=1e-08,
reduce=None,
reduction='mean'
)KL散度(相对熵)
1
2
3
4
5
6torch.nn.KLDivLoss(
size_average=None,
reduce=None,
reduction='mean',
log_target=False
)MarginRankingLoss
1
2
3
4
5
6torch.nn.MarginRankingLoss(
margin=0.0,
size_average=None,
reduce=None,
reduction='mean'
)二分类损失函数
1
2
3
4
5torch.nn.SoftMarginLoss(
size_average=None,
reduce=None,
reduction='mean'
)多标签边界损失函数
1
2
3
4
5torch.nn.MultiLabelMarginLoss(
size_average=None,
reduce=None,
reduction='mean'
)多分类的折页损失
1
2
3
4
5
6
7
8torch.nn.MultiMarginLoss(
p=1,
margin=1.0,
weight=None,
size_average=None,
reduce=None,
reduction='mean'
)三元组损失
1
2
3
4
5
6
7
8
9torch.nn.TripletMarginLoss(
margin=1.0,
p=2.0,
eps=1e-06,
swap=False,
size_average=None,
reduce=None,
reduction='mean'
)HingEmbeddingLoss
1
2
3
4
5
6torch.nn.HingeEmbeddingLoss(
margin=1.0,
size_average=None,
reduce=None,
reduction='mean'
)CTC损失函数
1
2
3
4
5torch.nn.CTCLoss(
blank=0,
reduction='mean',
zero_infinity=False
)
PyTorch的优化器
深度学习的目标是通过不断改变网络参数,使得参数能够对输入做各种非线性变换拟合输出,从本质上讲就是一个复杂函数去寻找最优解
有以下两种方法计算深度神经网络的系数:
- 暴力穷举一遍参数,这种方法的实施可能性为0
- BP+优化器逼近求解。
优化器根据网络反向传播的梯度信息来更新网络的参数,从而降低损失函数计算值,这样就使得模型输出更加接近真实标签
PyTorch提供torch.optim优化器框架,包含了一下几种优化器
- torch.optim.ASGD
- torch.optim.Adadelta
- torch.optim.Adagrad
- torch.optim.Adam
- torch.optim.AdamW
- torch.optim.Adamax
- torch.optim.LBFGS
- torch.optim.RMSprop
- torch.optim.Rprop
- torch.optim.SGD
- torch.optim.SparseAdam
以上这些优化算法均继承于Optimizer类,基类定义如下:
1 | class Optimizer(object): |
在使用过程中还需要注意:每个优化器都是一个类,要先进行实例化
训练和评估
在完成上一篇博文的设置和本篇博文上述部分的了解后就可以正式加载数据训练模型了
训练状态下模型的参数应该支持反向传播的修改;如果是验证或测试状态,则不应该修改模型参数。在PyTorch中模型的状态设置非常简便,如下的两个操作二选一即可:
1 | model.train() #训练状态 |
训练时不需要再使用PyTorch内置的迭代器处理数据集,只要使用for循环读取DataLoader中的全部数据即可,代码如下
1 | for data, label in train_loader: |
注意要根据模型特征定义损失函数,这里使用预先定义的criterion
1 | loss = criterion(output, label) |
需要注意:开始新一批次训练时,应当先将优化器的梯度置零:
1 | optimizer.zero_grad() |
随后就要将数据放到CPU/GPU上进行后续计算,这里以使用Cuda的GPU加速为例
1 | data, label = data.cuda(), label.cuda() |
将损失函数loss反向传播回网络,同时使用优化器更新模型参数
1 | loss.backward() |
这样一次训练就完成了
测试的流程基本与训练过程一致,不同点在于:
- 需要预先设置torch.no_grad,以及将model调至eval模式
- 不需要将优化器的梯度置零
- 不需要将损失函数loss反向传播
- 不需要更新优化器
一个完整的训练过程如下所示:
1 | def train(epoch): |
对应的,一个完整的验证过程如下所示:
1 | def val(epoch): |
示例
下面以LeNet手写数字识别的PyTorch实现为例将这两篇的内容综述一遍
1 | import torch |
